
Machine learning (ML) has become an integral part of modern technology, powering applications that range from recommendation systems and image recognition to fraud detection and predictive analytics. One of the foundational distinctions in ML lies in understanding the difference between supervised and unsupervised learning. These two learning approaches are the primary ways that algorithms learn from data, each with distinct goals, techniques, and applications. For anyone entering the field, grasping the fundamentals of these two learning types is essential to understanding the broader scope of machine learning.
In this post, we’ll explore the key differences between supervised and unsupervised learning, the types of problems each one addresses, and their common applications.
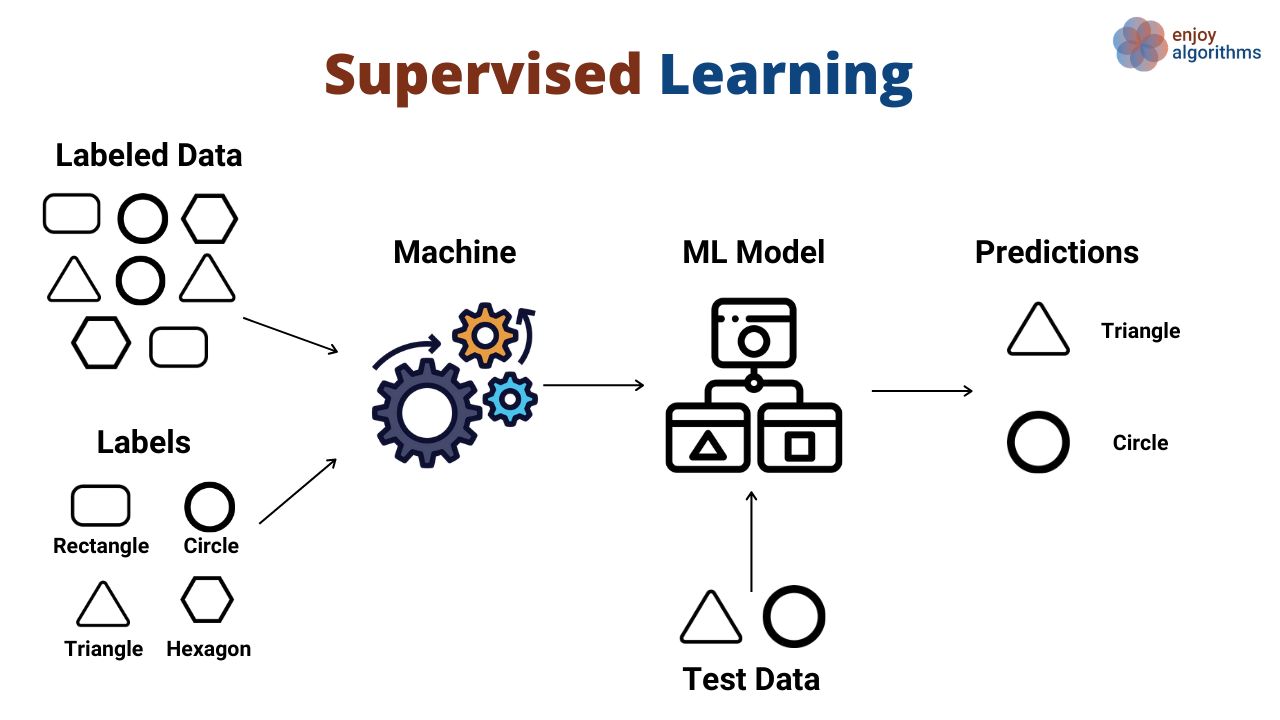
What is Supervised Learning?
In learning within machine learning systems the algorithm is trained using labeled data sets where each data point has an output or target label to guide its learning process effectively and make accurate predictions, for unseen data by minimizing errors, between predicted and actual labels through training supervision.
Key Characteristics of Supervised Learning:
- Labeled Data: Each data point in the training set has a known label, allowing the algorithm to learn the input-output relationship.
- Predictive Focus: The goal is to predict an output based on input data.
- Feedback Loop: The algorithm’s performance is assessed against the known labels, creating a feedback loop to improve accuracy.
Examples of Supervised Learning Algorithms:
- Linear Regression: Used for predicting continuous values.
- Logistic Regression: Useful for binary classification problems.
- Decision Trees and Random Forests: Popular for both classification and regression.
- Help Vector Products (SVM): Generally employed for classification tasks.
- Neural Networks: Employed in complex applications like image and speech recognition.
What is Unsupervised Learning?
In contrast to supervised learning, unsupervised learning deals with unlabeled data, meaning the algorithm does not have predefined labels or outcomes to guide its training. Instead, the algorithm attempts to identify patterns, clusters, or structures within the data on its own. Without labeled outputs, the goal in unsupervised learning is more exploratory—seeking to understand the underlying structure of the data rather than making specific predictions.
Key Characteristics of Unsupervised Learning:
- Unlabeled Data: The data lacks explicit output labels, forcing the algorithm to find structure on its own.
- Pattern Recognition: The primary goal is to detect patterns, groupings, or anomalies within the data.
- Exploratory Focus: The objective is more about discovering insights rather than predicting outcomes.
Examples of Unsupervised Learning Algorithms:
- K-Means Clustering: Teams information in to clusters centered on similarity.
- Hierarchical Clustering: Creates a hierarchy of clusters, useful for data with nested groupings.
- Principal Component Analysis (PCA): Reduces dimensionality by finding principal components, simplifying the dataset.
- Anomaly Detection: Identifies unusual data points that do not fit the general pattern.
Key Differences Between Supervised and Unsupervised Learning
Here’s a desk summarizing the main element variations between watched and unsupervised understanding:
| Feature | Supervised Learning | Unsupervised Learning |
| Data Labeling | Uses labeled data with known outcomes | Operates on unlabeled data, discovering structure on its own |
| Goal | Predicting specific outcomes based on input data | Finding patterns, clusters, or structure within the data |
| Algorithm Types | Linear Regression, SVM, Neural Networks, Decision Trees | K-Means Clustering, PCA, Hierarchical Clustering, Anomaly Detection |
| Complexity | More computationally intensive due to labeled data and feedback | Typically less computationally intensive, as there’s no label dependency |
| Accuracy and Evaluation | Measured using accuracy, precision, recall, etc. | Assessed using clustering metrics like silhouette score |
Practical Applications of Supervised and Unsupervised Learning
Credits: medium.com/@metehankozan/
Source: https://medium.com/@metehankozan/supervised-and-unsupervised-learning-an-intuitive-approach-cd8f8f64b644
Both supervised and unsupervised learning have unique applications, with each method suitable for different types of tasks.
Applications of Supervised Learning
- Image and Object Recognition: Supervised learning is used in applications like facial recognition, object detection, and handwriting recognition, where labeled images help train models to classify or identify objects.
- Fraud Detection: Banks and financial institutions use supervised learning to identify fraudulent transactions by training models on historical transaction data, labeled as either “fraud” or “not fraud.”
- Spam Detection: Email platforms use supervised learning to classify messages as spam or not, helping users avoid unwanted emails.
- Predictive Maintenance: Supervised learning can predict equipment failures by analyzing labeled sensor data, reducing downtime and maintenance costs.
- Sentiment Analysis: Supervised learning models are trained to classify text as positive, negative, or neutral, enabling businesses to gauge customer opinions.
Applications of Unsupervised Learning
- Customer Segmentation: Companies use unsupervised learning to group customers based on purchasing patterns, demographic information, and other behaviors, aiding in targeted marketing.
- Anomaly Detection: Unsupervised learning identifies unusual patterns in data, useful for detecting fraud, network intrusions, or equipment malfunctions.
- Topic Modeling: In natural language processing, unsupervised algorithms group similar documents or words, making it easier to categorize large amounts of text.
- Recommender Systems: Unsupervised learning techniques help create recommendation systems by analyzing user behavior patterns, suggesting similar items without explicit labeling.
- Dimensionality Reduction: Unsupervised learning reduces the complexity of large datasets by compressing them into fewer dimensions, simplifying visualization and analysis.
Challenges and Limitations
Supervised Learning Challenges:
- Data Labeling Requirements: Supervised learning requires extensive labeled data, which can be costly and time-consuming to obtain.
- Overfitting Risk: If a model learns too closely from the training data, it may fail to generalize to new data.
Unsupervised Learning Challenges:
- Lack of Evaluation Metrics: Without labeled data, assessing accuracy and performance can be difficult.
- Data Quality Dependence: Poor-quality data can lead to misleading patterns, as the algorithm has no labels to guide it.
Choosing Between Supervised and Unsupervised Learning
Picking between administered and unsupervised learning depends upon the problem’s nature, the option of marked data, and the required outcome.
- When to Use Supervised Learning: If labeled data is available and the goal is to predict outcomes or classify data, supervised learning is ideal. This approach works well in structured environments with clear objectives.
- When to Use Unsupervised Learning: When dealing with unlabeled data, unsupervised learning is suitable for exploring patterns and relationships. It’s beneficial in exploratory data analysis and when trying to understand data without specific outcomes in mind.
Conclusion: Understanding the Value of Supervised and Unsupervised Learning
Supervised and unsupervised learning play roles, in machine learning with uses and methods tailored for distinct purposes and applications; supervised learning shines in predicting and categorizing tasks while unsupervised learning proves invaluable in uncover valuable insights within data lacking labels. Understanding the contrast between these approaches equips data scientists and machine learning enthusiasts to choose the method, for addressing their data obstacles.
As machine learning continues to evolve, knowing when to use supervised or unsupervised learning will remain essential for developing effective, data-driven solutions across industries. With both methods in your toolkit, you can unlock the full potential of your data and apply insights to drive innovation and success.

